이 게시물은 다음 링크를 참조하여 학습했습니다.
GitHub - WeareSoft/tech-interview: 🙍 tech interview
:loudspeaker:🙍 tech interview. Contribute to WeareSoft/tech-interview development by creating an account on GitHub.
github.com
데이터베이스 풀
Connection Pool
- 클라이언트의 요청에 따라 각 어플리케이션의 스레드에서 데이터베이스에 접근하기 위해서는 Connection(= 객체)이 필요하다.
- Connection pool은 이런 Connection을 여러 개 생성해 두어 저장해 놓은 공간(캐시), 또는 이 공간의 Connection을 필요할 때 꺼내 쓰고 반환하는 기법을 말한다.

DB에 접근하는 단계
1. 웹 컨테이너가 실행되면서 DB와 연결된 Connection 객체들을 미리 생성하여 pool에 저장한다.
2. DB에 요청 시, pool에서 Connection 객체를 가져와 DB에 접근한다.
3. 처리가 끝나면 다시 pool에 반환한다.

Connction이 부족하면?
- 모든 요청이 DB에 접근하고 있고 남은 Conncetion이 없다면, 해당 클라이언트는 대기 상태로 전환시키고 Pool에 Connection이 반환되면 대기 상태에 있는 클라이언트에게 순차적으로 제공된다.
왜 사용할까?
- 매 연결마다 Connection 객체를 생성하고 소멸시키는 비용을 줄일 수 있다.
- 미리 생성된 Connection 객체를 사용하기 때문에, DB 접근 시간이 단축된다.
- DB에 접근하는 Connection의 수를 제한하여, 메모리와 DB에 걸리는 부하를 조정할 수 있다.
Thread Pool
- 비슷한 맥락으로 Thread pool이라는 개념도 있다.
- 이 역시 매 요청마다 요청을 처리할 Thread를 만드는것이 아닌, 미리 생성한 pool 내의 Thread를 소멸시키지 않고 재사용하여 효율적으로 자원을 활용하는 기법.
Thread Pool과 Connection pool
- WAS에서 Thread pool과 Connection pool내의 Thread와 Connection의 수는 직접적으로 메모리와 관련이 있기 때문에, 많이 사용하면 할수록 메모리를 많이 점유하게 된다. 그렇다고 반대로 메모리를 위해 적게 지정한다면, 서버에서는 많은 요청을 처리하지 못하고 대기 할 수 밖에 없다.
- 보통 WAS의 Thread의 수가 Conncetion의 수보다 많은 것이 좋은데, 그 이유는 모든 요청이 DB에 접근하는 작업이 아니기 때문이다.
정규화
데이터 베이스 키(Key)
1. 후보키(Candidate Key)
릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 부분집합
모든 릴레이션은 반드시 하나 이상의 후보키를 가져야 함
릴레이션 내의 모든 튜플에 대해서 유일성과 최소성을 만족
2. 기본키(Primary Key)
후보키 중에서 선택한 주키(Main Key)
Null값을 가질 수 없다(개체무결성 1번째 조건)
기본키로 정의된 속성에는 동일한 값이 중복 저장 X(개체무결성 2번째 조건)
3. 대체키(Alternate Key)
후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
4. 슈퍼키(Super Key)
한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
뭉쳤을 때 유일성이 생기고, 흩어지면 몇몇 속성들은 독자적으로 유일성 있는 키로 사용 X
즉, 유일성은 만족하지만, 최소성은 만족 X
5. 외래키(Foreign Key)
관계(Relation)를 맺고 있는 릴레이션 R1, R2에서 R1이 참조하고 있는 R2의 기본키와 같은 R1의 속성
참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는데 중요한 도구
외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력할 수 없다(참조무결성 조건)
정규화
- 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것
- 무결성 유지 보장
- DB의 저장 용량 줄일 수 있음
정규화의 종류
제1 정규화
- 테이블의 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분해
제2 정규화
- 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해
- 완전 함수 종속 : 기본키의 부분집합이 결정자가 되어선 안된다는 것
제3 정규화
- 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해
- 이행적 종속 : A -> B, B -> C가 성립할 때 A -> C
BCNF 정규화
- 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해
** 데이터베이스 키 https://limkydev.tistory.com/108
** 정규화 https://mangkyu.tistory.com/110
트랜잭션
- 데이터베이스의 상태를 변환시키는 하나의 논리적인 작업 단위
- 데이터베이스 응용 프로그램은 트랜잭션들의 집합으로 정의 할 수 있다.
- 예를들어, A계좌에서 B계좌로 일정 금액을 이체한다고 가정하자.
1) A계좌의 잔액을 확인한다.
2) A계좌의 금액에서 이체할 금액을 빼고 다시 저장한다.
3) B계좌의 잔액을 확인한다.
4) B계좌의 금액에서 이체할 금액을 더하고 다시 저장한다.
- 이러한 과정들이 모두 합쳐져 계좌이체라는 하나의 작업단위를 구성한다
- 하나의 트랜잭션은 Commit 되거나 Rollback 된다
Commit : 한 개의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝나 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다.
Rollback : 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더라도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소(Undo)하는 연산이다. Rollback 시에는 해당 트랜잭션을 재시작하거나 폐기한다.
트랜잭션의 성질(ACID)
원자성(Atomicity), All or nothing
- 트랜잭션의 모든 연산들은 정상적으로 수행 완료되거나 아니면 전혀 어떠한 연산도 수행되지 않은 상태를 보장해야 한다.
일관성(Consistency)
- 트랜잭션 완료 후에도 데이터베이스가 일관된 상태로 유지되어야 한다.
독립성(Isolation)
- 하나의 트랜잭션이 실행하는 도중에 변경한 데이터는 이 트랜잭션이 완료될 때까지 다른 트랜잭션이 참조하지 못한다.
지속성(Durability)
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다.
트랜잭션의 필요성
- 현금 인출기를 작동하는 도중에 기계 오류나 정전 등과 같은 예기치 않은 상황이 발생하여 카드가 나오지 않거나 기계가 멈추는 경우
- 각각 다른 지점의 은행에서 동시에 인출할 때, 하나의 지점이 다른 지점에서 저장한 잔액을 덮어 쓰는 경우
- 위와 같은 상황이 발생되지 않도록 방지하기 위해, 즉, 트랜잭션의 성질인 ACID를 제공받기위해 트랜잭션을 사용한다.

트랜잭션의 상태
활동(Active)
- 트랜잭션이 실행 중에 있는 상태, 연산들이 정상적으로 실행 중인 상태
장애(Failed)
- 트랜잭션이 실행에 오류가 발생하여 중단된 상태
철회(Aborted)
- 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태
부분 완료(Partially Committed)
- 트랜잭션이 마지막 연산까지 실행했지만, Commit 연산이 실행되기 직전의 상태
완료(Committed)
- 트랜잭션이 성공적으로 종료되어 Commit 연산을 실행한 후의 상태
트랜잭션 격리 수준(Transaction Isolation Level)
- 트랜잭션에서 일관성이 없는 데이터를 허용하도록 하는 수준
- 데이베이스에서 트랜잭션이 ACID하기 위해 Locking 개념이 등장, 무조건적인 Locking은 성능을 저하, 이를 위해 Isolation Level 등장
Isolation Level의 종류
Read Uncommitted(레벨 0)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리지 않는 Level
- 트랜잭션에 처리중인 혹은 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용한다.
- 데이터베이스의 일관성을 유지할 수 없다.
Read Comitted(레벨 1)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리는 Level
- 트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없어 대기하게 된다.(Commit이 이루어진 트랜잭션만 조회 가능)
- SQL Server가 Defalut로 사용하는 Isolation Level
Repeatable Read(레벨 2)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 Level
- 트랜잭션이 범위 내에서 조회한 데이터의 내용이 항상 동일함을 보장한다.
- 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정이 불가능
Serializable(레벨 3)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 Level
- 완벽한 읽기 일관성 모드를 제공한다.
- 따라서, 다른 사용자는 그 영역에 해당되는 데이터에 대한 수정 및 입력이 불가능하다.
낮은 단계의 Isolation Level 이용시 발생하는 현상
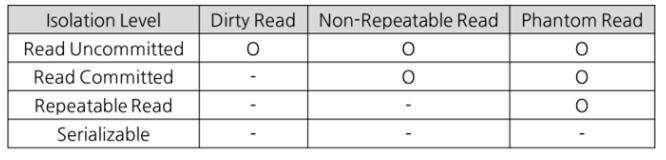
Dirty Read
- 커밋되지 않은 수정 중인 데이터를 다른 트랜잭션에서 읽을 수 있도록 허용할 때 발생하는 현상
- 어떤 트랜잭션에서 아직 실행이 끝나지 않은 다른 트랜잭션에 의한 변경 사항을 보게 되는 경우
Non-Repeatable Read
- 한 트랜잭션에서 같은 쿼리를 두 번 수행할 때 그 사이에 다른 트랜잭션이 값을 수정 또는 삭제함으로써
- 두 쿼리의 결과가 상이하게 나타나는 비일관성 현상
Phantom Read
- 한 트랜잭션 안에서 일정 범위의 레코드를 두 번 이상 읽을 때, 첫 번째 쿼리에서 없던 레코드가 두 번째 쿼리에서 나타나는 현상
- 이는 트랜잭션 도중 새로운 레코드가 삽입되는 것을 허용하기 때문에 나타난다.
** Isolation Level https://suhwan.dev/2019/06/09/transaction-isolation-level-and-lock/
** Isolation Level2 https://joont92.github.io/db/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98-%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80-isolation-level/
** Lock https://skasha.tistory.com/51
** Phantom Read https://sabarada.tistory.com/117
** Phantom Read 2 https://hleee.medium.com/%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80-3287d4bcc64d
Join
한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것
관계형 데이터베이스의 구조적 특징으로 정규화를 수행하면 의미 있는 데이터의 집합으로 테이블이 구성되고, 각 테이블끼리는 관계(Relationship)를 갖게 된다.
서로 관계있는 데이터가 여러 테이블로 나뉘어 저장되므로, 각 테이블에 저장된 데이터를 효과적으로 검색하기 위해 Join이 필요
조인을 사용할 때는 SQL 문장의 의미를 제대로 파악하고, 명확한 조인 조건을 제공해야 한다.
조인의 종류
1. 내부 조인(INNER JOIN)
- 가장 흔한 결합 방식이며 기본 조인 형식으로 간주한다.
- 명시적 조인(explicit), 암시적 조인(implicit) 2개의 다른 조인식 구문
- 명시적 조인(explicit) : JOIN 키워드 사용
- 암시적 조인(implicit) : SELECT 구문의 FROM 절에서 조인을 위한 여러 테이블을 나열
a. 동등 조인(EQUI JOIN) : 비교자 기반의 조인이며, 조인 구문에서 동등 비교만을 사용
b. 자연 조인(NATURAL JOIN) : 동등 조인의 한 유형
c. 교차 조인(CROSS JOIN) : 조인되는 두 테이블에서 곱집합을 반환한다.
2. 외부 조인(OUTER JOIN)
- 조인 대상 테이블에서 특정 테이블의 데이터가 모두 필요한 상황에서 외부 조인을 활용하여 효과적으로 결과 집합 생성 가능
a. 왼쪽 외부 조인(LEFT OUTER JOIN) : 우측 테이블에 조인할 컬럼의 값이 없는 경우 사용. 즉, 좌측 테이블의 모든 데이터를 포함하는 결과 집합 생성
b. 오른쪽 외부 조인(RIGHT OUTER JOIN) : 좌측 테이블에 조인할 컬럼의 값이 없는 경우 사용. 즉, 우측 테이블의 모든 데이터를 포함하는 결과 집합 생성
c. 완전 외부 조인(FULL OUTER JOIN) : 양쪽 테이블 모두 OUTER JOIN이 필요할 때 사용.
3. 셀프 조인(SELF JOIN)
한 테이블에서 자기 자신에 조인을 시키는 것
SQL Injection
보안상의 허점을 의도적으로 이용해, 악의적인 SQL 문을 실행하여 DB를 비정상적으로 조작하는 공격방법
SQL Injection의 종류
Error based SQL Injection
- 논리적 에러를 이용한 SQL Injection
Union based SQL Injection
- Union 명령어를 이용한 SQL Injection, UNION -> 두 개의 쿼리문에 대한 결과를 통합 보여줌
Blind SQL Injection
- 데이터베이스로부터 특정한 값이나 데이터를 전달받지 않고, 참/거짓 정보만을 알 수 있을 때 사용
- Boolean based SQL
- Time based SQL
Stored Procedure SQL Injection
- 저장된 프로시저에서의 SQL Injection, 일련의 쿼리들을 하나의 함수처럼 사용
-> 공격 난이도가 높지만, 서버에 직접 피해 입힐 수 있음
Mass SQL Injection
- 다량의 SQL Injection, 기존의 SQL Injection과 달리 한 번의 공격으로 다량의 데이터베이스 조작
SQL Injection 대응 방안
입력 값에 대한 검증
- 서버단에서 화이트리스트 기반으로 검증.
Prepared Statement 구문 사용
- 사용자의 입력 값이 데이터베이스의 파라미터로 들어가기 전에 DBMS가 미리 컴파일하여 실행하지 않고 대기. -> 입력값을 문자열로 인식
Error Message 노출 금지
- 데이터베이스 에러 발생 시, 에러 내용을 사용자에게 숨김(별도의 페이지 or 대화상자)
웹 방화벽
- 웹 공격 방어에 특화되어있는 웹 방화벽을 사용한다.
**SQL Injection https://noirstar.tistory.com/264
Index
원래 뜻은 색인. DB에서 조회 및 검색을 더 빠르게 할 수 있는 방법/기술 or 자료구조를 의미
데이터 양이 많을 때 탐색에서의 시간 및 자원 절약 용도
Index Table에서 값을 1차 탐색 후, Index 값을 바탕으로 재탐색
일반적으로 사용되는 알고리즘은 B+ Tree 알고리즘
B+ Tree 알고리즘

B+ Tree 장점
- B+ Tree 노드는 어떤 리프노드에 이르는 한 개의 경로만 검색하면 되므로 효율적
- 부등호 연산을 포함한 SELECT문에서 효율적
B+ Tree 단점
- 무분별한 인덱스 사용은 성능 저하 유발
- 기본적으로 이진트리 형식으로 저장되어 있기 때문에, 잦은 데이터의 변경(삽입, 수정, 삭제)은 성능 저하 유발
- 데이터의 중복이 높은 컬럼은 인덱스로 만들어도 무용지물
B+ Tree 구성
- 실제 데이터가 저장된 리프노드(Leaf nodes)
- 리프노드까지의 경로 역할을 하는 논리프노드(Non-leaf nodes)
- 경로의 출발점이 되는 루트 노드(Root node)
Statement vs PreparedStatement
가장 큰 차이점은 캐시(cache) 사용여부이다.
1) 준비 – 2) 컴파일 – 3) 실행 과정을 Statement는 매 쿼리마다, PreparedStatement는 처음 한번만 거친 후 캐시에 담아 재사용 한다.
Statement
- SQL 구문을 실행하는 역할
- 스스로는 SQL 구문 이해 못함
PreparedStatement
- Statement 클래스의 기능 향상
- 매개변수 사용 특화
** https://sas-study.tistory.com/160
** https://devbox.tistory.com/entry/Comporison
RDBMS vs NoSQL
RDBMS(Realtional DataBase Management System)
관계형 데이터베이스 관리 시스템
외래 키를 이용한 테이블 간 Join 가능
데이터 구조가 명확하며 변경 될 여지가 없으며 명확한 스키마가 중요한 경우 사용
NoSQL(Not Only SQL)
관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술
테이블 간 Join 불가능
성능을 극대화 하기위해 데이터의 일관성을 포기
정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용
** https://khj93.tistory.com/entry/Database-RDBMS%EC%99%80-NOSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90
효과적인 쿼리 사용
** https://mangkyu.tistory.com/52
옵티마이저
- 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할 수행
- SQL문을 작성할 때 요구사항만 작성될 뿐, 처리과정에 대한 기술은 하지 않기 때문
- 옵티마이저는 규칙기반 옵티마이저, 비용기반 옵티마이저로 나뉜다.

규칙기반 옵티마이저(RBO, Rule Based Optimizer)
- 실행속도가 빠른 순으로 규칙을 먼저 세워두고 우선순위가 앞서는 방법을 채택
- 판단 기준이 분명하므로 사용자도 예측 가능
- 요즘은 많이 사용하지 않지만, 규칙을 알아두면 효과적인 쿼리문 작성에 도움이 됨
비용기반 옵티마이저(CBO, Cost Based Optimizer)
- 여러 계획에 대한 비용을 산정해 보고 그 중에서 최소 비용 선택
- 사용자가 미리 예측하기 어려움
- 최근 많이 사용, 오라클 10 이후 버전부터 공식적 사용
** 옵티마이저 정의 https://dataonair.or.kr/db-tech-reference/d-guide/sql/?mod=document&uid=354
** 옵티마이저 종류 https://coding-factory.tistory.com/743
Replication vs Clustering
Replication
- 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축
- Master Node는 쓰기 작업만 처리, Slave Node는 읽기 작업만 처리
Replication 장점
- DB요청의 대부분이 읽기 작업이기 때문에 Replication만으로도 성능을 높일 수 있음
- 비동기 방식으로 운영되어 지연 시간이 거의 없음
Replication 단점
- 노드들 간의 데이터 동기화가 보장되지 않아 일관성있는 데이터를 얻지 못할 수 있다.
- Master 노드가 다운되면 복구 및 대처가 까다롭다
Clustering
- 여러 개의 DB를 수평적인 구조로 구축하는 방식
- 동기 방식으로 노드들간의 데이터 동기화
Clustering 장점
- 노드들 간의 데이터를 동기화하여 일관성있는 데이터 얻을 수 있음
- 1개의 노드가 죽어도 다른 노드가 살아 있어 시스템을 계속 장애없이 운영 가능
Clustering 단점
- 데이터를 동기화 하는 시간이 필요하므로 Replication에 비해 쓰기 성능이 떨어짐
- 장애가 전파된 경우 처리가 까다로우며, 데이터 동기화에 의해 스케일링 한계가 있음
** Replication https://nesoy.github.io/articles/2018-02/Database-Replication
** Replication vs Clustering https://mangkyu.tistory.com/97
파티셔닝(Partitioning)
서비스의 크기가 점점 커지게 되면서 DB 또한 커지게 되며 용량의 한계와 성능의 저하를 가져오게 됨
이를 해결하기 위해 큰 테이블을 관리하기 쉬운 ‘파티션(partition)’이라는 작은 단위로 나누어 관리
성능적, 관리적 측면에서의 장점을 가짐
JOIN 비용이 증가, table과 index를 같이 파티셔닝 해야하는 단점을 가짐
파티셔닝의 종류
1. 수평 파티셔닝(Horizontal Partitioning) - 하나의 테이블의 각 행을 다른 테이블에 분산시킴
샤딩과 동일한 개념
2. 수직 파티셔닝(Vertical Partitioning) - 테이블의 일부 열을 빼내는 형태로 분할
파티셔닝의 분할 기준
1. 범위 분할(range partitioning)
2. 목록 분할(list partitioning)
3. 해시 분할(hash partitioning)
4. 합성 분할(composite partitioning)
** https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
** https://nesoy.github.io/articles/2018-02/Database-Partitioning
'CS' 카테고리의 다른 글
| OS(Operating System) (0) | 2022.01.21 |
|---|---|
| Network (0) | 2022.01.21 |